Contrastive Language-Image Pretraining
- 1 min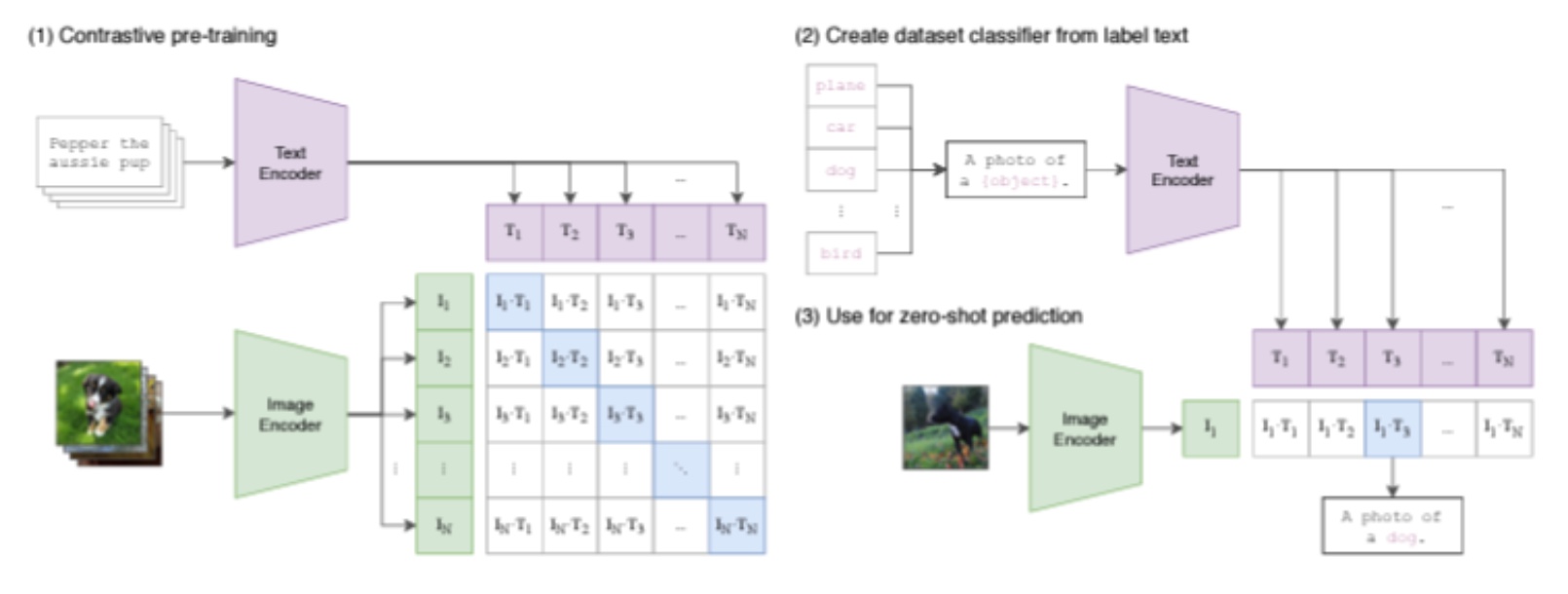
Neural networks are commonly used for computer vision systems which can be applied to various fields with high performance. However, current computer vision systems have few weaknesses since they can only predict a fixed set of predetermined object categories. This restriction limits computer vision systems generality and usability as more and more labeled data is required to predict another visual concepts. In order to reduce the limitation, computer vision systems can learn about images from raw texts. Thus, the study are reproducing the research paper “Learning Transferable Visual Models From Natural Language Supervision”. The paper proves that a simple pre-training about predicting caption and image pair is an efficient and scalable way to learn image representations from dataset of 400 million (image, text) pairs collected from the internet. After pre-training, natural language is used to reference learned visual concepts (or describe new ones enabling zero-shot transfer of the model to downstream tasks. The study shows the performance of this approach by benchmarking on over 30 different existing computer vision datasets, spanning tasks such as OCR, action recognition in videos, geo-localization, and many types of fine-grained object classification. By utilizing approaches in the paper, the we conduct an experiment by comparing the performance of CLIP zero-shot classification and that of linear probe with ResNet-50.